

Please visit https://roysoumya.github.io/ for my complete and updated research portfolio.
My name is Soumyadeep Roy. I am a Ph.D. Candidate in Computer Science and Engineering Department at IIT Kharagpur, West Bengal, India. My thesis topic is “Incorporating Domain Knowledge in Medical NLP Applications.” I work under the supervision of Prof. Niloy Ganguly and Prof. Shamik Sural. I am also part of the Complex Networks Research Group(CNeRG), IIT Kharagpur.
Thesis topic: Incorporating Domain Knowledge in Medical NLP Applications

Research publications
Soumyadeep Roy, Jonas Wallat, Sowmya S Sundaram, Wolfgang Nejdl, Niloy Ganguly, GeneMask: Fast Pretraining of Gene Sequences to Enable Few-shot Learning, in the 26th European Conference on Artificial Intelligence (ECAI) 2023, September 30 – October 5, 2023, Krakow, Poland, (Core A conference) [Code][arXiv][Slides]
Soumyadeep Roy, Niloy Ganguly, Shamik Sural, Koustav Rudra, Interpretable Clinical Trial Search using Pubmed Citation Network, in the 2023 IEEE International Conference on Digital Health (ICDH), July 2 to 8, 2023, Chicago, United States, doi: 10.1109/ICDH60066.2023.00056 [Paper][Code][Slides] Candidate for Best Student Paper Award
Soumyadeep Roy, Sudip Chakraborty, Aishik Mandal, Prakhar Sharma, Gunjan Balde, Anandhavelu Natarajan, Megha Khosla, Shamik Sural and Niloy Ganguly, Developing Knowledge-Aware Neural Models for Medical Forum Question Classification, in the 30th ACM International Conference on Information and Knowledge Management (CIKM), 1-5 November 2021, Online (Short Paper) [Code][arXiv][DOI][Slides][Video]
Soumyadeep Roy, Shamik Sural, Niyati Chhaya, Anandhavelu Natarajan, and Niloy Ganguly, An Integrated Approach for Improving Brand Consistency of Web Content: Modeling, Analysis, and Recommendation, in ACM Transactions on the Web (TWEB), 25 pages, November 2020 (Journal) [arXiv][DOI] [Slides-MS Thesis version] [Code and Data]
Soumyadeep Roy, Koustav Rudra, Nikhil Agrawal, Shamik Sural, Niloy Ganguly, Towards an Aspect-based Ranking Model for Clinical Trial Search, in the 8th International Conference on Computational Data and Social Networks (CSoNet 2019), November 18 – 20, 2019, Ho Chi Minh City, Vietnam (Full Paper) [PDF] [DOI] [Code] [Data][Slides]
Soumyadeep Roy, Niloy Ganguly, Shamik Sural, Niyati Chhaya, and Anandhavelu Natarajan, Understanding Brand Consistency from Web Content, in Proceedings of the 10th ACM Conference on Web Science, WebSci 19, (Boston, MA, USA), pp. 245–253, ACM, 2019. (Full Paper) [DOI] [PDF] [Slides][Data]
Soumyadeep Roy, Nibir Pal, Kousik Dasgupta, Binay Gupta; Understanding Email Interactivity and Predicting User Response to email, In Methodologies and Application Issues of Contemporary Computing Framework, pp. 69-79. Springer, Singapore, 2018 (Book Chapter) [DOI][Paper][Code][Slides]
Soumyadeep Roy; Automated EBM-oriented Summarization of Active or Recruiting Clinical Trials at COMSNETS 2018 held at Bangalore, India on January 3 – 7, 2018 [Link] Best Graduate Forum Presentation Award
Research Projects
Project A: Patient subtyping in Parkinson’s disease and Schizophrenia using clinical and genomic data
Motivation: Parkinson‘s Disease (PD) is a complex neurodegenerative disorder with high heterogeneity in clinical symptoms (motor and non-motor), progression course, treatment response, and genetic factors. Patient subtyping helps improve disease mechanism understanding and facilitates targeted interventions or treatment regimes.
Current Situation: Most PD subtypes are based on motor symptoms and do not focus on non-motor symptoms. General phenotype-based approaches do not provide a personalized way, and approaches considering phenotype and genotype data together are not well-explored.
Solution and Vision: We aim to develop data-driven patient subtyping methods that integrate both motor and non-motor characteristics of PD and jointly utilize clinical and genotype data. These automatically learned subtypes would be examined to identify potential markers for neurodegenerative diseases like PD.
With the help of these predictive markers, early therapeutic intervention in neurodegenerative diseases could be realized. We are working closely with Prof. Dr. Helge Frieling of the Department of Psychiatry, Social Psychiatry and Psychotherapy (MHH) and other biomedical partners at MHH associated with the Leibniz AI Lab.
Here, we will initially focus on young-onset PD patients and patients with comorbidities like schizophrenia and severe depression. Our final goal will be to develop personalized AI-based solutions to assist doctors with their day-to-day clinical practice.
Project B: Knowledge-Guided Efficient Representation Learning for Genomic Applications
Understanding gene regulatory code and developing deep learning models for gene sequence representation learning have become active areas of research.
Learning better representations is quite difficult due to the polysemy and distant semantic relationship, which prior methods often fail to capture, especially in data-scarce scenarios.
Further, these models do not utilize gene-related biomedical domain knowledge. For each downstream task, a separate fine-tuned model is required and may lead to issues like catastrophic forgetting.
We will discuss how we try to address some of these challenges and our initial results. We evaluate gene sequence-level classification tasks like promoter region prediction, chromatin profile prediction, and promoter-enhancer interaction prediction.
Project C: Developing an Aspect-based Search System for Clinical Trials Search
Publications: CSoNet 2019 Full paper
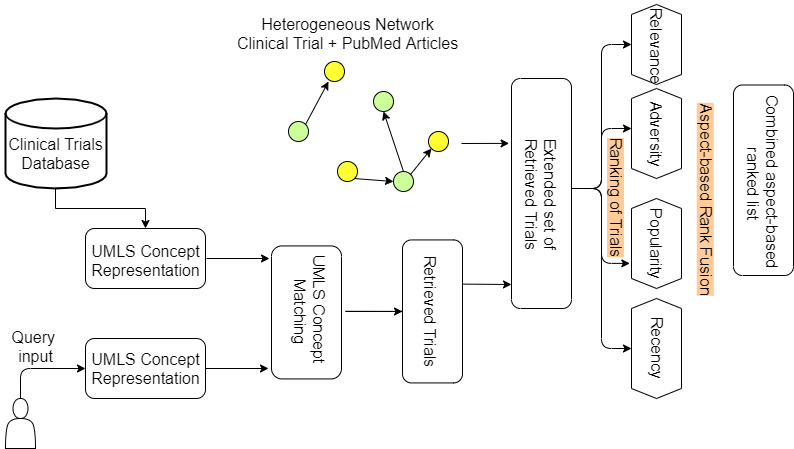
Abstract: Clinical Trials are crucial for the practice of evidence-based medicine. It provides updated and essential health-related information for the patients. Sometimes, Clinical trials are the first source of information about new drugs and treatments.
Different stakeholders, such as trial volunteers, trial investigators, and meta-analyses researchers, often need to search for trials. In this paper, we propose an automated method to retrieve relevant trials based on the overlap of UMLS concepts between the user query and clinical trials.
However, different stakeholders may have different information needs, and accordingly, we rank the retrieved clinical trials based on the following four aspects – Relevancy, Adversity, Recency, and Popularity.
We aim to develop a clinical trial search system that covers multiple disease classes instead of only focusing on retrieving oncology-based clinical trials. We follow a rigorous annotation scheme and create an annotated retrieval set for 25 queries across five disease categories.
Our proposed method performs better than the baseline model in almost 90% of cases. We also measure the correlation between the different aspect-based ranking lists and observe a high negative Spearman rank’s correlation coefficient between popularity and recency.
Keywords: Clinical trial search, Aspect-based ranking, Biomedical information retrieval
Completed Projects
Developing an integrated framework for understanding brand consistency from online content
Publications: WebSci 2019 Full paper, TWEB Journal Paper 2021
Abstract: A consumer-dependent (business-to-consumer) organization tends to present itself as possessing a set of human qualities, which is a company’s brand perception.
The perception is impressed upon the consumer through the content (be it in the form of advertisements, blogs, or magazines) produced by the organization. In this digital marketing era, a continuous generation of web content is needed to keep up consumer engagement and thus make a lasting impression on them.
However, such content authoring at scale introduces challenges in maintaining consistency in a brand’s messaging tone.
Thus the first task is to develop a quantitative technique to check whether the desired brand personality is maintained in a published article.
In the first work, we quantify brand personality and formulate its linguistic features. We develop five independent classification models to score text articles extracted from brand communications on five personality dimensions: sincerity, excitement, competence, ruggedness, and sophistication.
We perform a large-scale data collection activity and collect around 300 K web page content that covers around 650 Fortune 1000 companies. We also develop a novel deep learning architecture that leverages transfer learning to improve our classifier performance further.
We also study the effect of directly adding linguistic features to our neural architecture. The classifier automatically identifies the web articles which are not consistent with the mission and vision of a company.
A consistent brand will generate trust and retain customers over time since consumers look for regularity and common patterns.
Studies have provided various strategies for maintaining the brand image over time and the impact of major company-related events like brand extension and mergers on it.
However, there is no standard measure that quantifies the extent of brand inconsistency for a given company.

Thus in the second chapter, we quantify brand consistency and study the company-level contributing factors like the effect of brand extensions.
We observe that promotion posts primarily portray competence as their brand personality across all brands and favor the brand consistency of companies that portrays competence in most of their posts (primary trait).
We find that the presence of brand extension-related posts reduces the brand consistency score of a company and that it is more challenging to maintain posts of a company with low topical consistency with the brand personality they want to evoke.
We discover companies that post consistently and find that financially affluent companies are better at maintaining consistency.
To address the brand inconsistency issue, we developed a helper tool that recommends the sentences that need to be modified to make the web article more consistent with the brand perception of the content writers.
Keywords: online reputation management, brand image, brand personality, brand consistency, text classification, transfer learning, sentence ranking
Brief Intro
I have been working on Machine Learning problems for the last five years. Through this page, firstly, I will share my experience on how to start working on real-life datasets. I have worked on projects as diverse as Weather, Email, Event Extraction from text, Emotion mining, Twitter, Online Reputation Monitoring, and Digital Health. I am no expert, but I feel it will help you to get started.
Secondly, I will share resources and news to make Computer Science research accessible and understandable to the general population. As of now, I will be targeting undergraduates and those starting their careers in research like me.
Some of my past projects range from scraping dynamic websites using Python to data cleaning using “dplyr” in R. Extensive preprocessing with climate data from NOAA in R and beginner Python projects from Automate the Boring Stuff With Python are available with full documented codes in my Github account. You can take a look if interested.
Please mention the topic you want me to write or any random question you have in the Contact section. I will surely get back to you as soon as possible.